Содержание статьи
Что такое маскирование данных?
Маскирование данных - это способ создать фальшивую, но реалистичную версию данных вашей организации. Цель состоит в том, чтобы защитить конфиденциальные данные, обеспечивая при этом функциональную альтернативу, когда реальные данные не нужны, например, при обучении пользователей, демонстрациях продаж или тестировании программного обеспечения.
Процессы маскирования данных изменяют значения данных при использовании того же формата. Цель состоит в том, чтобы создать версию, которую невозможно расшифровать или реконструировать. Есть несколько способов изменить данные, включая перемешивание символов, замену слов или символов и шифрование.
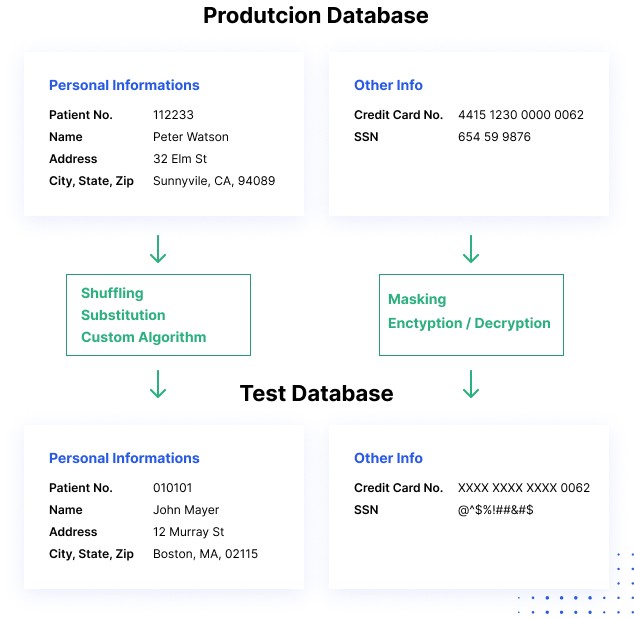
Как работает маскирование данных.
Почему важно маскирование данных?
Вот несколько причин, по которым маскирование данных важно для многих организаций:
Типы маскирования данных
Существует несколько типов маскировки данных, которые обычно используются для защиты конфиденциальных данных.
Статическое маскирование данных
Процессы статического маскирования данных могут помочь вам создать очищенную копию базы данных. Процесс изменяет все конфиденциальные данные до тех пор, пока копия базы данных не станет безопасной для совместного использования. Обычно процесс включает создание резервной копии базы данных в производственной среде, загрузку ее в отдельную среду, удаление любых ненужных данных и затем маскирование данных, пока они находятся в стазисе. Затем замаскированная копия может быть перемещена в целевое местоположение.
Детерминированное маскирование данных
Включает отображение двух наборов данных, которые имеют один и тот же тип данных, таким образом, что одно значение всегда заменяется другим значением. Например, имя «Джон Смит» всегда заменяется на «Джим Джеймсон» везде, где оно встречается в базе данных. Этот метод удобен для многих сценариев, но по своей сути менее безопасен.
Маскирование данных на лету
Маскирование данных при их передаче из производственных систем в системы тестирования или разработки перед сохранением данных на диск. Организации, которые часто развертывают программное обеспечение, не могут создать резервную копию исходной базы данных и применить маскирование - им нужен способ непрерывной потоковой передачи данных из производственной среды в несколько тестовых сред.
«На лету» маскирование отправляет меньшие подмножества замаскированных данных, когда это необходимо. Каждое подмножество замаскированных данных хранится в среде разработки / тестирования для использования в непроизводственной системе.
Важно применять маскирование на лету к любому каналу из производственной системы в среду разработки в самом начале проекта разработки, чтобы предотвратить проблемы с соблюдением требований и безопасностью.
Динамическое маскирование данных
Подобно маскированию на лету, но данные никогда не хранятся во вторичном хранилище данных в среде разработки / тестирования. Скорее, он передается напрямую из производственной системы и используется другой системой в среде разработки / тестирования.
Методы маскировки данных
Давайте рассмотрим несколько распространенных способов, которыми организации применяют маскировку к конфиденциальным данным. При защите данных ИТ-специалисты могут использовать различные методы.
Шифрование данных
Когда данные зашифрованы, они становятся бесполезными, если у зрителя нет ключа дешифрования. По сути, данные маскируются алгоритмом шифрования. Это наиболее безопасная форма маскирования данных, но она также сложна в реализации, поскольку требует технологии для непрерывного шифрования данных, а также механизмов для управления ключами шифрования и обмена ими.
Скремблирование данных
Персонажи реорганизованы в случайном порядке, заменяя исходное содержимое. Например, идентификационный номер, такой как 76498 в производственной базе данных, может быть заменен на 84967 в тестовой базе данных. Этот метод очень просто реализовать, но он может применяться только к некоторым типам данных и менее безопасен.
Обнуление
Данные кажутся отсутствующими или «нулевыми» при просмотре неавторизованным пользователем. Это делает данные менее полезными для целей разработки и тестирования.
Разница в значениях
Исходные значения данных заменяются функцией, например разницей между наименьшим и наибольшим значением в ряду. Например, если клиент приобрел несколько продуктов, покупная цена может быть заменена диапазоном между самой высокой и самой низкой уплаченной ценой. Это может предоставить полезные данные для многих целей, не раскрывая исходный набор данных.
Подмена данных
Значения данных заменяются поддельными, но реалистичными альтернативными значениями. Например, настоящие имена клиентов заменяются случайным выбором имен из телефонной книги.
Перемешивание данных
Аналогично замене, за исключением того, что значения данных переключаются в одном наборе данных. Данные перегруппированы в каждом столбце с использованием случайной последовательности; например, переключение между реальными именами клиентов в нескольких записях клиентов. Выходной набор выглядит как реальные данные, но не отображает реальную информацию для каждого отдельного человека или записи данных.
Псевдонимизация
Согласно Общему регламенту ЕС по защите данных (GDPR), был введен новый термин, охватывающий такие процессы, как маскирование данных, шифрование и хеширование для защиты личных данных: псевдонимизация.
Псевдонимизация, как определено в GDPR, - это любой метод, который гарантирует, что данные не могут быть использованы для личной идентификации. Это требует удаления прямых идентификаторов и, желательно, избегания множественных идентификаторов, которые при объединении могут идентифицировать человека.
Кроме того, ключи шифрования или другие данные, которые можно использовать для восстановления исходных значений данных, должны храниться отдельно и надежно.
Рекомендации по маскированию данных
Определите объем проекта
Чтобы эффективно выполнять маскировку данных, компании должны знать, какую информацию необходимо защитить, кто имеет право ее видеть, какие приложения используют данные и где они находятся, как в производственной, так и в непроизводственной областях. Хотя на бумаге это может показаться простым, из-за сложности операций и множества направлений бизнеса этот процесс может потребовать значительных усилий и должен планироваться как отдельный этап проекта.
Обеспечьте ссылочную целостность
Ссылочная целостность означает, что каждый «тип» информации, поступающей из бизнес-приложения, должен маскироваться с использованием одного и того же алгоритма.
В крупных организациях использование единого инструмента маскирования данных для всего предприятия невозможно. От каждого направления бизнеса может потребоваться реализовать собственное маскирование данных из-за требований бюджета / бизнеса, различных практик ИТ-администрирования или различных требований безопасности / нормативных требований.
Убедитесь, что различные инструменты и методы маскирования данных в организации синхронизированы при работе с одним и тем же типом данных. Это предотвратит проблемы в будущем, когда данные нужно будет использовать в разных бизнес-направлениях.
Защитите алгоритмы маскировки данных
Очень важно подумать о том, как защитить алгоритмы создания данных, а также альтернативные наборы данных или словари, используемые для шифрования данных. Поскольку только авторизованные пользователи должны иметь доступ к реальным данным, эти алгоритмы следует считать чрезвычайно чувствительными. Если кто-то узнает, какие повторяемые алгоритмы маскирования используются, он сможет реконструировать большие блоки конфиденциальной информации.
Лучшая практика маскирования данных, которая явно требуется некоторыми нормативными актами, заключается в обеспечении разделения обязанностей. Например, специалисты по ИТ-безопасности определяют, какие методы и алгоритмы будут использоваться в целом, но конкретные настройки алгоритмов и списки данных должны быть доступны только владельцам данных в соответствующем отделе.
Маскирование данных с помощью системы
Система защиты - это решение безопасности, которое обеспечивает возможности маскирования и шифрования данных, позволяя скрывать конфиденциальные данные, чтобы они были бесполезны для злоумышленника, даже если они каким-то образом извлечены.
Помимо маскировки данных, решение по обеспечению безопасности данных защищает ваши данные, где бы они ни находились - локально, в облаке или в гибридных средах. Он также предоставляет ИТ-отделам полную информацию о том, как осуществляется доступ к данным, как они используются и перемещаются по организации.
Наш комплексный подход основан на нескольких уровнях защиты, включая:
- Что такое маскирование данных?
- Почему важно маскирование данных?
- Типы маскирования данных
- Методы маскировки данных
- Рекомендации по маскированию данных
- Маскирование данных с помощью системы
Что такое маскирование данных?
Маскирование данных - это способ создать фальшивую, но реалистичную версию данных вашей организации. Цель состоит в том, чтобы защитить конфиденциальные данные, обеспечивая при этом функциональную альтернативу, когда реальные данные не нужны, например, при обучении пользователей, демонстрациях продаж или тестировании программного обеспечения.
Процессы маскирования данных изменяют значения данных при использовании того же формата. Цель состоит в том, чтобы создать версию, которую невозможно расшифровать или реконструировать. Есть несколько способов изменить данные, включая перемешивание символов, замену слов или символов и шифрование.
Как работает маскирование данных.
Почему важно маскирование данных?
Вот несколько причин, по которым маскирование данных важно для многих организаций:
- Маскирование данных устраняет несколько критических угроз - потерю данных, кражу данных, внутренние угрозы или компрометацию учетной записи, а также небезопасные интерфейсы со сторонними системами.
- Снижает риски данных, связанные с внедрением облака.
- Делает данные бесполезными для злоумышленника, сохраняя при этом многие присущие им функциональные свойства.
- Позволяет обмениваться данными с авторизованными пользователями, такими как тестировщики и разработчики, не раскрывая производственные данные.
- Может использоваться для очистки данных - обычное удаление файлов по-прежнему оставляет следы данных на носителе, в то время как при очистке старые значения заменяются замаскированными.
Типы маскирования данных
Существует несколько типов маскировки данных, которые обычно используются для защиты конфиденциальных данных.
Статическое маскирование данных
Процессы статического маскирования данных могут помочь вам создать очищенную копию базы данных. Процесс изменяет все конфиденциальные данные до тех пор, пока копия базы данных не станет безопасной для совместного использования. Обычно процесс включает создание резервной копии базы данных в производственной среде, загрузку ее в отдельную среду, удаление любых ненужных данных и затем маскирование данных, пока они находятся в стазисе. Затем замаскированная копия может быть перемещена в целевое местоположение.
Детерминированное маскирование данных
Включает отображение двух наборов данных, которые имеют один и тот же тип данных, таким образом, что одно значение всегда заменяется другим значением. Например, имя «Джон Смит» всегда заменяется на «Джим Джеймсон» везде, где оно встречается в базе данных. Этот метод удобен для многих сценариев, но по своей сути менее безопасен.
Маскирование данных на лету
Маскирование данных при их передаче из производственных систем в системы тестирования или разработки перед сохранением данных на диск. Организации, которые часто развертывают программное обеспечение, не могут создать резервную копию исходной базы данных и применить маскирование - им нужен способ непрерывной потоковой передачи данных из производственной среды в несколько тестовых сред.
«На лету» маскирование отправляет меньшие подмножества замаскированных данных, когда это необходимо. Каждое подмножество замаскированных данных хранится в среде разработки / тестирования для использования в непроизводственной системе.
Важно применять маскирование на лету к любому каналу из производственной системы в среду разработки в самом начале проекта разработки, чтобы предотвратить проблемы с соблюдением требований и безопасностью.
Динамическое маскирование данных
Подобно маскированию на лету, но данные никогда не хранятся во вторичном хранилище данных в среде разработки / тестирования. Скорее, он передается напрямую из производственной системы и используется другой системой в среде разработки / тестирования.
Методы маскировки данных
Давайте рассмотрим несколько распространенных способов, которыми организации применяют маскировку к конфиденциальным данным. При защите данных ИТ-специалисты могут использовать различные методы.
Шифрование данных
Когда данные зашифрованы, они становятся бесполезными, если у зрителя нет ключа дешифрования. По сути, данные маскируются алгоритмом шифрования. Это наиболее безопасная форма маскирования данных, но она также сложна в реализации, поскольку требует технологии для непрерывного шифрования данных, а также механизмов для управления ключами шифрования и обмена ими.
Скремблирование данных
Персонажи реорганизованы в случайном порядке, заменяя исходное содержимое. Например, идентификационный номер, такой как 76498 в производственной базе данных, может быть заменен на 84967 в тестовой базе данных. Этот метод очень просто реализовать, но он может применяться только к некоторым типам данных и менее безопасен.
Обнуление
Данные кажутся отсутствующими или «нулевыми» при просмотре неавторизованным пользователем. Это делает данные менее полезными для целей разработки и тестирования.
Разница в значениях
Исходные значения данных заменяются функцией, например разницей между наименьшим и наибольшим значением в ряду. Например, если клиент приобрел несколько продуктов, покупная цена может быть заменена диапазоном между самой высокой и самой низкой уплаченной ценой. Это может предоставить полезные данные для многих целей, не раскрывая исходный набор данных.
Подмена данных
Значения данных заменяются поддельными, но реалистичными альтернативными значениями. Например, настоящие имена клиентов заменяются случайным выбором имен из телефонной книги.
Перемешивание данных
Аналогично замене, за исключением того, что значения данных переключаются в одном наборе данных. Данные перегруппированы в каждом столбце с использованием случайной последовательности; например, переключение между реальными именами клиентов в нескольких записях клиентов. Выходной набор выглядит как реальные данные, но не отображает реальную информацию для каждого отдельного человека или записи данных.
Псевдонимизация
Согласно Общему регламенту ЕС по защите данных (GDPR), был введен новый термин, охватывающий такие процессы, как маскирование данных, шифрование и хеширование для защиты личных данных: псевдонимизация.
Псевдонимизация, как определено в GDPR, - это любой метод, который гарантирует, что данные не могут быть использованы для личной идентификации. Это требует удаления прямых идентификаторов и, желательно, избегания множественных идентификаторов, которые при объединении могут идентифицировать человека.
Кроме того, ключи шифрования или другие данные, которые можно использовать для восстановления исходных значений данных, должны храниться отдельно и надежно.
Рекомендации по маскированию данных
Определите объем проекта
Чтобы эффективно выполнять маскировку данных, компании должны знать, какую информацию необходимо защитить, кто имеет право ее видеть, какие приложения используют данные и где они находятся, как в производственной, так и в непроизводственной областях. Хотя на бумаге это может показаться простым, из-за сложности операций и множества направлений бизнеса этот процесс может потребовать значительных усилий и должен планироваться как отдельный этап проекта.
Обеспечьте ссылочную целостность
Ссылочная целостность означает, что каждый «тип» информации, поступающей из бизнес-приложения, должен маскироваться с использованием одного и того же алгоритма.
В крупных организациях использование единого инструмента маскирования данных для всего предприятия невозможно. От каждого направления бизнеса может потребоваться реализовать собственное маскирование данных из-за требований бюджета / бизнеса, различных практик ИТ-администрирования или различных требований безопасности / нормативных требований.
Убедитесь, что различные инструменты и методы маскирования данных в организации синхронизированы при работе с одним и тем же типом данных. Это предотвратит проблемы в будущем, когда данные нужно будет использовать в разных бизнес-направлениях.
Защитите алгоритмы маскировки данных
Очень важно подумать о том, как защитить алгоритмы создания данных, а также альтернативные наборы данных или словари, используемые для шифрования данных. Поскольку только авторизованные пользователи должны иметь доступ к реальным данным, эти алгоритмы следует считать чрезвычайно чувствительными. Если кто-то узнает, какие повторяемые алгоритмы маскирования используются, он сможет реконструировать большие блоки конфиденциальной информации.
Лучшая практика маскирования данных, которая явно требуется некоторыми нормативными актами, заключается в обеспечении разделения обязанностей. Например, специалисты по ИТ-безопасности определяют, какие методы и алгоритмы будут использоваться в целом, но конкретные настройки алгоритмов и списки данных должны быть доступны только владельцам данных в соответствующем отделе.
Маскирование данных с помощью системы
Система защиты - это решение безопасности, которое обеспечивает возможности маскирования и шифрования данных, позволяя скрывать конфиденциальные данные, чтобы они были бесполезны для злоумышленника, даже если они каким-то образом извлечены.
Помимо маскировки данных, решение по обеспечению безопасности данных защищает ваши данные, где бы они ни находились - локально, в облаке или в гибридных средах. Он также предоставляет ИТ-отделам полную информацию о том, как осуществляется доступ к данным, как они используются и перемещаются по организации.
Наш комплексный подход основан на нескольких уровнях защиты, включая:
- Брандмауэр базы данных - блокирует внедрение SQL-кода и другие угрозы при оценке известных уязвимостей.
- Управление правами пользователей - отслеживает доступ к данным и действия привилегированных пользователей для выявления чрезмерных, несоответствующих и неиспользуемых привилегий.
- Предотвращение потери данных (DLP) - проверяет данные в движении, в состоянии покоя на серверах, в облачном хранилище или на конечных устройствах.
- Аналитика поведения пользователей - устанавливает базовые параметры поведения при доступе к данным, использует машинное обучение для обнаружения аномальных и потенциально рискованных действий и оповещения о них.
- Обнаружение и классификация данных - выявляет расположение, объем и контекст данных локально и в облаке.
- Мониторинг активности баз данных - отслеживает реляционные базы данных, хранилища данных, большие данные и мэйнфреймы для генерации предупреждений в реальном времени о нарушениях политики.
- Приоритизация предупреждений - система использует технологии искусственного интеллекта и машинного обучения для анализа потока событий безопасности и определения приоритетов наиболее важных из них.