Содержание статьи
Что такое обфускация данных?
Обфускация данных - это процесс замены конфиденциальной информации данными, которые выглядят как реальная производственная информация, что делает ее бесполезной для злоумышленников. Он в основном используется в среде тестирования или разработки - разработчикам и тестировщикам нужны реалистичные данные для создания и тестирования программного обеспечения, но им не нужно видеть реальные данные.
Существует три основных метода обфускации данных:
Три метода обфускации данных
Почему важно обфускация данных?
Вот несколько основных причин, по которым организации полагаются на методы обфускации данных:
Что такое маскирование данных?
Маскирование данных - это процесс замены реальных данных поддельными данными, идентичными по структуре и типу данных. Например, телефонный номер 212-648-3399 можно заменить на другой действительный, но поддельный номер телефона, например 567-499-3788.
Есть два основных типа маскировки данных: статическая и динамическая.
Статическое маскирование данных
Статическое маскирование данных включает маскирование данных в исходной базе данных с последующим их копированием в среду разработки или тестирования. Это делает безопасным предоставление доступа к базе данных подрядчикам или неавторизованным сотрудникам.
Динамическое маскирование данных
Динамическое маскирование данных (DDM) - это более продвинутый метод, который поддерживает два набора данных в одной базе данных: исходные конфиденциальные данные и замаскированную копию. По умолчанию приложения и пользователи видят замаскированные данные, а реальная копия данных доступна только авторизованным ролям. DDM обычно достигается путем передачи данных неавторизованным сторонам через обратный прокси.
Что такое шифрование данных?
Шифрование включает в себя скремблирование данных или обычного текста с использованием алгоритма шифрования таким образом, чтобы его нельзя было расшифровать без ключа шифрования. Современные алгоритмы шифрования очень безопасны и требуют невероятных вычислительных мощностей для взлома.
Существует два основных типа шифрования: симметричное и асимметричное или шифрование с открытым ключом.
Симметричное шифрование ключа
Шифрование с симметричным ключом шифрует и расшифровывает сообщение или файл с использованием одного и того же ключа. Это намного быстрее, чем асимметричное шифрование, но отправитель должен обменяться ключом шифрования с получателем перед расшифровкой.
Симметричное шифрование требует, чтобы пользователи распределяли и безопасно управляли большим количеством ключей, что непрактично и создает проблемы с безопасностью. Вот почему большинство современных решений для шифрования основаны на криптографии с открытым ключом.
Криптография с открытым ключом
Криптография с открытым ключом (также известная как асимметричное шифрование) использует два ключа: открытый ключ и закрытый ключ. Открытый ключ может быть передан кому угодно, а закрытый ключ защищен. Система шифрования с открытым ключом использует алгоритм, который требует комбинации закрытого и открытого ключей для разблокировки сообщения.
Алгоритм RSA - широко используемая система криптографии с открытым ключом. Он обычно используется для цифровых подписей, которые могут гарантировать конфиденциальность, целостность и подлинность электронных сообщений.
Определение токенизации
Токенизация заменяет конфиденциальную информацию эквивалентной неконфиденциальной информацией. Данные замены называются токеном.
Токены могут быть созданы несколькими способами:
Другие методы обфускации данных
Вот несколько других методов, которые ваша организация может использовать для обфускации данных в непроизводственной среде:
4-этапная стратегия обфускации данных
Чтобы добиться успеха в проекте обфускации данных, ваша организация должна разработать целостный подход к планированию, управлению данными и выполнению.
1. Обнаружение данных
Первый шаг в плане обфускации данных - определить, какие данные необходимо защитить. У каждой компании есть определенные требования к безопасности, сложности данных, внутренним политикам и требованиям соответствия. Конечным результатом этого шага является определение классов данных, определение риска утечки данных из каждого класса и степень, в которой обфускация данных может снизить риск.
2. Архитектура
На этапе обнаружения данных организация может классифицировать данные на основе бизнес-классов, функциональных классов или классов, предусмотренных стандартом соответствия, таким как PCI / DSS. Типичная классификация - это общедоступные, конфиденциальные и секретные данные.
Для тех классов, которые необходимо защитить с помощью обфускации, необходимо тщательно протестировать, как различные типы обфускации повлияют на приложение. Бизнес-операция должна нормально функционировать при непрерывном скрытии данных.
3. Сборка
На этом этапе организация создает решение для практического выполнения обфускации и настраивает его в соответствии с ранее определенными классами данных и архитектурой. Это включает в себя:
4. Тестирование и развертывание
После создания системы ее следует тщательно протестировать на всех соответствующих данных и приложениях, чтобы убедиться, что обфускация действительно безопасна и не влияет на бизнес-операции. Тестирование включает создание одного или нескольких тестовых хранилищ данных и попытку скрыть хотя бы часть производственного набора данных.
По мере продвижения проекта к развертыванию организация должна выполнить приемочное тестирование пользователей (UAT), определить организационные роли, которые будут нести ответственность за обфускацию, и создать сценарии, которые могут автоматизировать обфускацию как часть рутинных бизнес-процессов.
Обфускация данных с помощью решений безопасности
Решение безопасности использует маскировку и шифрование данных для сокрытия основных данных, поэтому они будут бесполезны для злоумышленника, даже если они каким-то образом будут получены.
Помимо обфускации, решение Imperva по обеспечению безопасности данных защищает ваши данные, где бы они ни находились - локально, в облаке или в гибридных средах. Он также предоставляет ИТ-отделам полную информацию о том, как осуществляется доступ к данным, как они используются и перемещаются по организации.
Наш комплексный подход основан на нескольких уровнях защиты, включая:
- Что такое обфускация данных?
- Почему важно обфускация данных?
- Что такое маскирование данных?
- Что такое шифрование данных?
- Определение токенизации
- Другие методы запутывания данных
- 4-этапная стратегия обфускации данных
- Обфускация данных с помощью решений безопасности
Что такое обфускация данных?
Обфускация данных - это процесс замены конфиденциальной информации данными, которые выглядят как реальная производственная информация, что делает ее бесполезной для злоумышленников. Он в основном используется в среде тестирования или разработки - разработчикам и тестировщикам нужны реалистичные данные для создания и тестирования программного обеспечения, но им не нужно видеть реальные данные.
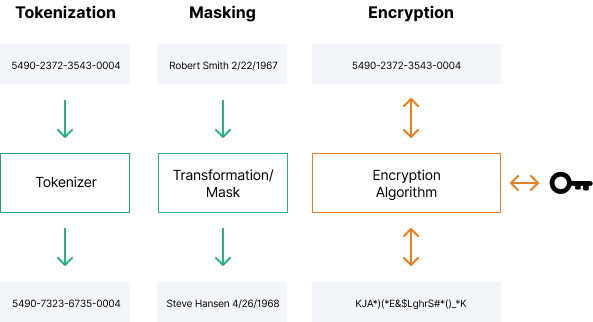
Существует три основных метода обфускации данных:
- Маскирование - это способ создания разных версий данных с похожей структурой. Тип данных не меняется, меняется только значение. Данные можно изменять разными способами, например, сдвигая числа или буквы, заменяя слова и переключая частичные данные между записями.
- Шифрование данных использует криптографические методы, обычно системы симметричных или закрытых / публичных ключей, для кодирования данных, что делает их полностью непригодными для использования до расшифровки. Шифрование очень безопасно, но когда вы шифруете свои данные, вы не можете ими манипулировать или анализировать.
- Токенизация данных заменяет определенные данные бессмысленными значениями. Однако авторизованные пользователи могут подключить токен к исходным данным. Данные токенов можно использовать в производственных средах, например, для выполнения финансовых транзакций без необходимости передавать номер кредитной карты внешнему процессору.
Три метода обфускации данных
Почему важно обфускация данных?
Вот несколько основных причин, по которым организации полагаются на методы обфускации данных:
- Третьим лицам нельзя доверять - отправка личных данных, информации о платежных картах или информации о здоровье третьим лицам опасна. Существует двойной риск: это увеличивает количество людей, имеющих доступ к данным, находящимся вне контроля организации, и подвергает организацию нарушениям правил и стандартов.
- Деловые операции могут не нуждаться в реальных данных - любое использование данных клиентов, сотрудников или пользователей является рискованным, поскольку оно открывает доступ к данным сотрудникам, подрядчикам и другим лицам. Многие бизнес-процессы, такие как разработка, тестирование, аналитика и отчетность, не обязательно должны обрабатывать реальные личные данные. Обфусцируя данные, организация может поддерживать бизнес-процесс, но устраняет риск.
- Соответствие - многие стандарты соответствия требуют, чтобы данные были скрыты при определенных условиях. Например, Общий регламент ЕС по защите данных (GDPR) четко оговаривает использование маскировки конфиденциальных данных, собранных о гражданах ЕС.
Что такое маскирование данных?
Маскирование данных - это процесс замены реальных данных поддельными данными, идентичными по структуре и типу данных. Например, телефонный номер 212-648-3399 можно заменить на другой действительный, но поддельный номер телефона, например 567-499-3788.
Есть два основных типа маскировки данных: статическая и динамическая.
Статическое маскирование данных
Статическое маскирование данных включает маскирование данных в исходной базе данных с последующим их копированием в среду разработки или тестирования. Это делает безопасным предоставление доступа к базе данных подрядчикам или неавторизованным сотрудникам.
Динамическое маскирование данных
Динамическое маскирование данных (DDM) - это более продвинутый метод, который поддерживает два набора данных в одной базе данных: исходные конфиденциальные данные и замаскированную копию. По умолчанию приложения и пользователи видят замаскированные данные, а реальная копия данных доступна только авторизованным ролям. DDM обычно достигается путем передачи данных неавторизованным сторонам через обратный прокси.
Что такое шифрование данных?
Шифрование включает в себя скремблирование данных или обычного текста с использованием алгоритма шифрования таким образом, чтобы его нельзя было расшифровать без ключа шифрования. Современные алгоритмы шифрования очень безопасны и требуют невероятных вычислительных мощностей для взлома.
Существует два основных типа шифрования: симметричное и асимметричное или шифрование с открытым ключом.
Симметричное шифрование ключа
Шифрование с симметричным ключом шифрует и расшифровывает сообщение или файл с использованием одного и того же ключа. Это намного быстрее, чем асимметричное шифрование, но отправитель должен обменяться ключом шифрования с получателем перед расшифровкой.
Симметричное шифрование требует, чтобы пользователи распределяли и безопасно управляли большим количеством ключей, что непрактично и создает проблемы с безопасностью. Вот почему большинство современных решений для шифрования основаны на криптографии с открытым ключом.
Криптография с открытым ключом
Криптография с открытым ключом (также известная как асимметричное шифрование) использует два ключа: открытый ключ и закрытый ключ. Открытый ключ может быть передан кому угодно, а закрытый ключ защищен. Система шифрования с открытым ключом использует алгоритм, который требует комбинации закрытого и открытого ключей для разблокировки сообщения.
Алгоритм RSA - широко используемая система криптографии с открытым ключом. Он обычно используется для цифровых подписей, которые могут гарантировать конфиденциальность, целостность и подлинность электронных сообщений.
Определение токенизации
Токенизация заменяет конфиденциальную информацию эквивалентной неконфиденциальной информацией. Данные замены называются токеном.
Токены могут быть созданы несколькими способами:
- Использование шифрования, которое можно отменить с помощью криптографического ключа.
- Использование хеш-функции - необратимой математической операции.
- Использование случайных чисел или порядковых номеров
Другие методы обфускации данных
Вот несколько других методов, которые ваша организация может использовать для обфускации данных в непроизводственной среде:
- Недетерминированная рандомизация - замена реального значения другим случайным значением в рамках определенных ограничений, которые гарантируют, что значение остается действительным. Например, убедитесь, что новое значение даты истечения срока действия кредитной карты является действительным месяцем в следующие пять лет.
- Перетасовка - Изменение порядок цифр номера или кода , который не имеет смыслового значения. Например, изменение номера телефона с 912-8876 на 876-7129.
- Размытие - добавление дисперсии к числу, оставаясь при этом в общей близости от исходного числа. Например, изменение суммы средств на банковском счете на случайное значение в пределах 10% от первоначальной суммы.
- Обнуление - замена исходных значений символом, представляющим нулевой символ, например, #### - #### - #### - 9887 для номера кредитной карты.
- Повторяемое маскирование - замена значения другим случайным значением, но с гарантией того, что исходные значения всегда сопоставляются с одними и теми же значениями замены. Это поддерживает ссылочную целостность.
- Подстановка - замена исходного числа одним значением из закрытого словаря значений - например, замена имени именем, случайно выбранным из списка из 10 000 возможных имен.
- Пользовательские правила - важно указать правила для сохранения достоверности специальных форматов данных, таких как номера социального страхования, адреса, номера телефонов и т.д Например, для выполнения обфускации адресов вам потребуется использовать географическую базу данных и убедиться, что вы заменяете каждый элемент адреса допустимым значением - номером улицы, названием улицы, городом, страной и т. д.
4-этапная стратегия обфускации данных
Чтобы добиться успеха в проекте обфускации данных, ваша организация должна разработать целостный подход к планированию, управлению данными и выполнению.
1. Обнаружение данных
Первый шаг в плане обфускации данных - определить, какие данные необходимо защитить. У каждой компании есть определенные требования к безопасности, сложности данных, внутренним политикам и требованиям соответствия. Конечным результатом этого шага является определение классов данных, определение риска утечки данных из каждого класса и степень, в которой обфускация данных может снизить риск.
2. Архитектура
На этапе обнаружения данных организация может классифицировать данные на основе бизнес-классов, функциональных классов или классов, предусмотренных стандартом соответствия, таким как PCI / DSS. Типичная классификация - это общедоступные, конфиденциальные и секретные данные.
Для тех классов, которые необходимо защитить с помощью обфускации, необходимо тщательно протестировать, как различные типы обфускации повлияют на приложение. Бизнес-операция должна нормально функционировать при непрерывном скрытии данных.
3. Сборка
На этом этапе организация создает решение для практического выполнения обфускации и настраивает его в соответствии с ранее определенными классами данных и архитектурой. Это включает в себя:
- Как интегрировать компонент обфускации данных с существующими хранилищами данных и приложениями
- Подготовка наборов данных и инфраструктуры хранения для хранения обфусцированных версий данных
- Как начать процесс управления изменениями.
- Определение правил обфускации для разных типов данных
4. Тестирование и развертывание
После создания системы ее следует тщательно протестировать на всех соответствующих данных и приложениях, чтобы убедиться, что обфускация действительно безопасна и не влияет на бизнес-операции. Тестирование включает создание одного или нескольких тестовых хранилищ данных и попытку скрыть хотя бы часть производственного набора данных.
По мере продвижения проекта к развертыванию организация должна выполнить приемочное тестирование пользователей (UAT), определить организационные роли, которые будут нести ответственность за обфускацию, и создать сценарии, которые могут автоматизировать обфускацию как часть рутинных бизнес-процессов.
Обфускация данных с помощью решений безопасности
Решение безопасности использует маскировку и шифрование данных для сокрытия основных данных, поэтому они будут бесполезны для злоумышленника, даже если они каким-то образом будут получены.
Помимо обфускации, решение Imperva по обеспечению безопасности данных защищает ваши данные, где бы они ни находились - локально, в облаке или в гибридных средах. Он также предоставляет ИТ-отделам полную информацию о том, как осуществляется доступ к данным, как они используются и перемещаются по организации.
Наш комплексный подход основан на нескольких уровнях защиты, включая:
- Брандмауэр базы данных - блокирует внедрение SQL-кода и другие угрозы при оценке известных уязвимостей.
- Управление правами пользователей - отслеживает доступ к данным и действия привилегированных пользователей для выявления чрезмерных, несоответствующих и неиспользуемых привилегий.
- Предотвращение потери данных (DLP) - проверяет данные в движении, в состоянии покоя на серверах, в облачном хранилище или на конечных устройствах.
- Аналитика поведения пользователей - устанавливает базовые параметры поведения при доступе к данным, использует машинное обучение для обнаружения аномальных и потенциально рискованных действий и оповещения о них.
- Обнаружение и классификация данных - выявляет расположение, объем и контекст данных в локальной среде и в облаке.
- Мониторинг активности баз данных - отслеживает реляционные базы данных, хранилища данных, большие данные и мэйнфреймы для генерации предупреждений в реальном времени о нарушениях политики.
- Приоритизация предупреждений - решения безопасности используют технологии искусственного интеллекта и машинного обучения для анализа потока событий безопасности и определения приоритетов наиболее важных из них.