
Carding 4 Carders
Professional
- Messages
- 2,724
- Reaction score
- 1,586
- Points
- 113

Всемирная паутина - интересный парадокс - она создана с помощью компьютеров, но для людей. Сайты, которые вы посещаете каждый день, используют естественный язык, изображения и макет страницы для представления информации в доступной для вас форме. Несмотря на то, что они играют центральную роль в создании и поддержании Интернета, сами компьютеры действительно не могут понять всю эту информацию. Они не могут читать, видеть отношения или принимать решения, как вы.
Semantic Web предлагает помощь компьютерам «читать» и использовать Интернет. Основная идея довольно проста - метаданные, добавленные к веб-страницам, могут сделать существующую всемирную паутину машиночитаемой. Это не наделит искусственным интеллектом и не сделает компьютеры самосознательными, но даст машинам инструменты для поиска, обмена и, в ограниченной степени, интерпретации информации. Это расширение, а не замена Всемирной паутины.
Возможно, это звучит немного абстрактно, и это так. Хотя на некоторых сайтах уже используются концепции семантической паутины, многие необходимые инструменты все еще находятся в разработке. В этой статье мы представим концепции и инструменты, лежащие в основе семантической паутины, на Земле, применив их к далекой-далекой галактике.
СОДЕРЖАНИЕ
- Почему семантическая сеть?
- Разметка: XML и RDF
- Что к чему: URI
- Языки и словари: RDFS, OWL и SKOS
- Связывая все вместе
- W3C и будущее семантической сети
Почему семантическая сеть?
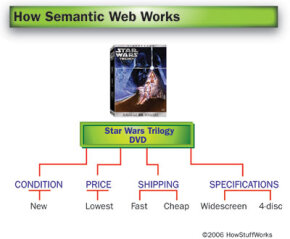
Предположим, вы хотите купить коробочный набор «Трилогия Звездных войн» в Интернете, и у вас есть несколько основных критериев для покупки. Во-первых, вам нужны широкоэкранные, а не полноэкранные DVD-диски, и вам нужен набор с дополнительным диском с бонусными материалами. Во-вторых, вам нужна самая низкая доступная цена, но вы предпочитаете покупать новый набор, а не подержанный. Наконец, вы не хотите слишком много платить за доставку и обработку, но вы также не хотите слишком долго ждать доставки.
На данном этапе развития Интернета вам лучше всего было бы просматривать веб-страницы различных розничных продавцов, сравнивая цены, а также время и расценки на доставку. Вы также можете найти сайт, на котором будут сравниваться цены и варианты доставки сразу у нескольких розничных продавцов. В любом случае, вы должны сделать большую часть виртуальной работы, а затем принять решение о покупке и оформить заказ самостоятельно.
С семантической сетью у вас будет другой вариант. Вы можете ввести свои предпочтения в компьютеризированный агент, который будет искать в Интернете, находить лучший вариант для вас и размещать ваш заказ. Затем агент может открыть программное обеспечение для личных финансов на вашем компьютере и записать потраченную вами сумму, а также отметить дату прибытия ваших DVD-дисков в вашем календаре. Ваш агент также узнает ваши привычки и предпочтения, поэтому, если у вас будет плохой опыт покупки на одном конкретном сайте, он будет знать, что не стоит использовать этот сайт снова.
Агент будет делать это не путем просмотра изображений и чтения описаний, как это делает человек, а путем поиска в метаданных, которые четко идентифицируют и определяют то, что агенту необходимо знать. Метаданные - это просто машиночитаемые данные, которые описывают другие данные. В семантической сети метаданные невидимы, когда люди читают страницу, но они четко видны компьютерам. Метаданные также могут способствовать более сложному и целенаправленному поиску в Интернете с более точными результатами. Перефразируя Тима Бернерса-Ли, изобретателя Всемирной паутины, эти инструменты позволят Интернету - в настоящее время похожему на гигантскую книгу - стать гигантской базой данных.
Далее мы рассмотрим инструменты, которые могут сделать документы машиночитаемыми.
Семантический
Чтобы сделать веб-сайт машиночитаемым, нужны слои и слои метаданных, логики и безопасности. Большинство визуальных представлений этих слоев представляют собой стопку - своего рода башню из блоков, которая представляет все слои. Стек меняется и развивается по мере развития концепций семантической паутины. Вы можете увидеть, как выглядит обычная версия стека здесь, как часть введения в Semantic Web.
Разметка: XML и RDF
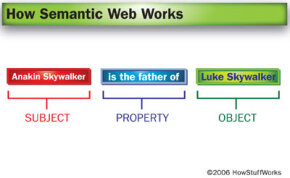
У тройки RDF есть субъект (Энакин Скайуокер), объект (Люк Скайуокер) и свойство, объединяющее их.
Допустим, вы хотите сделать это предложение доступным для чтения на компьютере.
Энакин Скайуокер - отец Люка Скайуокера.
Вам легко понять, что означает это предложение - Энакин и Люк Скайуокер - оба люди, и между ними есть отношения. Вы знаете, что отец - это тип родителей, и что предложение также означает, что Люк - сын Анакина. Но компьютер не может ничего понять без посторонней помощи. Чтобы компьютер мог понять, что означает это предложение, вам нужно добавить машиночитаемую информацию, которая описывает, кто такие Анакин и Люк и каковы их отношения. Это начинается с двух инструментов - расширяемого языка разметки (XML) и структуры описания ресурсов (RDF).
XML - это язык разметки, подобный языку разметки гипертекста (HTML), с которым вы, вероятно, немного знакомы по работе в Интернете. HTML определяет внешний вид информации, которую вы просматриваете в Интернете. XML дополняет (но не заменяет) HTML, добавляя теги, описывающие данные. Эти теги невидимы для людей, читающих документ, но видимы для компьютеров. Теги уже используются в Интернете, и существующие боты, такие как боты, собирающие данные для поисковых систем, могут их читать.
RDF делает именно то, что указывает его название - используя теги XML, он обеспечивает структуру для описания ресурсов. С точки зрения RDF, практически все в мире является ресурсом. Эта структура связывает ресурс (любое существительное, например, Энакин Скайуокер или трилогия «Звездных войн») с конкретным элементом или местом в сети, чтобы компьютер точно знал, что это за ресурс. Четкое определение ресурсов не дает компьютеру делать такие вещи, как спутать Энакина Скайуокера с Себастьяном Шоу или Хайденом Кристиансеном или оригинальную трилогию с трилогией «Звездных войн» одного человека.
Для этого RDF использует тройки, записанные в виде тегов XML, чтобы представить эту информацию в виде графа. Эти тройки состоят из подлежащего, свойства и объекта, которые подобны подлежащему, глаголу и прямому объекту предложения. (Некоторые источники называют их субъектом, предикатом и объектом.) RDF уже существует в сети - например, он является частью создания RSS-канала.
Пока что в этом примере компьютер знает, что в этом предложении есть два объекта и что между ними существует связь. Но он не знает, что это за объекты и как они соотносятся друг с другом. Далее мы рассмотрим инструмент для добавления этого смыслового слоя.
Что к чему: URI
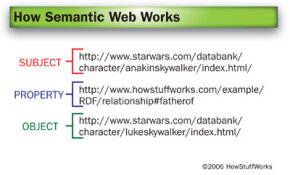
URI дает компьютеру конкретную точку отсчета для каждого элемента в тройке - нет необходимости в интерпретации или возможном недопонимании.
Даже со структурой, предоставляемой XML и RDF, компьютеру по-прежнему нужен очень прямой, конкретный способ понимания того, кто или что это за ресурсы. Для этого RDF использует универсальные идентификаторы ресурсов (URI), чтобы направить компьютер к документу или объекту, представляющему ресурс. Вы уже знакомы с наиболее распространенной формой URI - унифицированным указателем ресурса (URL), который начинается с http://. URI может указывать на что угодно в Интернете, а также может указывать на объекты, которые не являются частью Интернета, например, бытовую технику в компьютеризированных домах. Адреса Mailto, ftp и telnet - это еще несколько примеров URI.
В нашем примере мы будем использовать страницы персонажей на официальном сайте «Звездных войн» в качестве их URI.
Теперь компьютер знает, что такое субъект и объект: Энакин Скайуокер - это сущность, представленная первым URI, а Люк Скайуокер - сущность, представленная вторым. Но вы заметите, что средний URI в нашей тройке - один для свойства - не указывает на сайт «Звездных войн». Вместо этого он указывает на вымышленный документ на сервере HowStuffWorks. Если бы эта страница действительно существовала, это было бы наше пространство имен XML.
В отличие от HTML, в котором используются стандартные теги, такие как <b> для жирного шрифта и <u> для подчеркивания, XML не имеет стандартных тегов. Это полезно - это позволяет разработчикам создавать уникальные теги для определенных целей. Но это означает, что браузер не знает автоматически, что означают теги. Пространство имен XML - это, по сути, документ, который сообщает приложениям значение всех тегов в другом документе. Создатель XML-документа объявляет пространство имен в начале документа строкой кода. В нашем примере объявление пространства имен будет выглядеть так:
<rdf: RDF xmlns: carding = https: //www.carder.market/example/RDF/relationship#>
Эта строка кода сообщает компьютеру: «Любые теги, которые начинаются с hsw, используют словарь, найденный в этом документе. Здесь вы можете найти любой тег, начинающийся с hsw». Таким образом, люди могут создавать XML-теги, которые им нужны для документа, без конфликта с другими XML-документами в Интернете.
XML и RDF являются «официальным языком» семантической паутины, но самих по себе их недостаточно, чтобы сделать всю сеть доступной для компьютера. Далее мы рассмотрим некоторые другие слои.
Это (не) невозможно!
XML и RDF лежат в основе семантической паутины. Они придают компьютерам структуру, в которой можно искать информацию и определять отношения между ресурсами. Приложения также могут объединять графы, использующие идентичные URI. Например, приложение может объединить приведенный выше график с другим, определяющим отношения между Энакином Скайуокером и Дартом Вейдером. Затем приложение может сделать вывод, что Вейдер - отец Люка.
Языки и словари: RDFS, OWL и SKOS

Пример очень небольшого количества ресурсов и соединений, которые можно найти в онтологии «Звездных войн». Вы можете понять это самостоятельно, просматривая фильмы и просматривая веб-страницы, но компьютер должен иметь четкую схему, чтобы понять это.
Еще одно препятствие для семантической паутины состоит в том, что у компьютеров нет того словарного запаса, который есть у людей. Вы использовали язык всю свою жизнь, поэтому вам, вероятно, легко увидеть связи между разными словами и понятиями и вывести значения на основе контекстов. К сожалению, нельзя просто дать компьютеру словарь, альманах и набор энциклопедий и позволить компьютеру выучить все это самостоятельно. Чтобы понять, что означают слова и каковы отношения между ними, компьютер должен иметь документы, которые описывают все слова и логику, чтобы установить необходимые связи.
В семантической сети это происходит из схем и онтологий . Это два связанных инструмента, помогающих компьютеру понимать человеческий словарный запас. Онтология - это просто словарь, который описывает объекты и то, как они соотносятся друг с другом. Схема - это метод организации информации. Как и в случае с тегами RDF, доступ к схемам и онтологиям включается в документы как метаданные, и создатель документа должен объявить, на какие онтологии ссылаются в начале документа.
Инструменты схемы и онтологии, используемые в семантической сети, включают:
- RDF Vocabulary Description Language schema (RDFS) - RDFS добавляет классы, подклассы и свойства к ресурсам, создавая базовую языковую структуру. Например, ресурс Dagobah является подклассом класса planet . Имущество Дагобы могло быть заболоченным.
- Простая система знаний организации (SKOS) - SKOS классифицирует ресурсы с точки зрения более широкой или более узкой, позволяет назначение предпочтительных и альтернативных меток и может позволить людям быстро порт тезаурусы и классификаторы в Интернете. Например, в глоссарии «Звездных войн» более узким термином для лорда ситхов может быть Дарт Сидиус, а более широким - злодей . Точно так же альтернативные ярлыки для Хана Соло могут быть « пастух по нерфу» и «лазерный мозг».
- Язык веб-онтологий (OWL) - OWL, наиболее сложный уровень, формализует онтологии, описывает отношения между классами и использует логику для выполнения выводов. Он также может создавать новые классы на основе существующей информации. OWL доступен в трех уровнях сложности - Lite, Description Language (DL) и Full.
Затем мы свяжем все это воедино, посмотрев на наш оригинальный пример - DVD-диски с «Трилогией Звездных войн».
Доступ к метаданным
Одна из долгосрочных целей семантической паутины - предоставить агентам, программным приложениям и веб-приложениям доступ к метаданным и их использование. Ключевым инструментом для этого является простой протокол и язык запросов RDF (SPARQL ), который все еще находится в разработке. Цель SPARQL - извлекать информацию из графиков RDF. Он может искать данные, ограничивать и сортировать результаты. Одним из преимуществ структуры RDF является то, что эти запросы могут быть очень точными и давать очень точные результаты.
Связывая все вместе
В нашем первоначальном примере мы говорили о покупке DVD-дисков со «Звездными войнами» в Интернете. Вот как семантическая сеть может упростить весь процесс:- На каждом сайте будут текст и изображения (для чтения) и метаданные (для чтения на компьютере), описывающие DVD-диски, доступные для покупки на их сайте.
- Метаданные, использующие тройки RDF и теги XML, сделают все атрибуты DVD (например, состояние и цену) машиночитаемыми.
- При необходимости предприятия будут использовать онтологии, чтобы дать компьютеру словарь, необходимый для описания всех этих объектов и их атрибутов. Все торговые сайты могут использовать одни и те же онтологии, поэтому все метаданные будут на одном языке.
- Каждый сайт, продающий DVD-диски, также будет использовать соответствующие меры безопасности и шифрования для защиты информации клиентов.
- Компьютеризированные приложения или агенты будут читать все метаданные, найденные на разных сайтах. Приложения также могут сравнивать информацию, проверяя, что источники являются точными и заслуживающими доверия.
Безопасность и доказательство
Как и любой веб-документ, семантическая сеть требует мер безопасности для защиты данных и транзакций. В рекомендации W3C для семантической паутины включены цифровые подписи, шифрование, доказательства и доверие. Доказательства и доверие связаны с логикой семантической паутины и способностями приложений проверять правильность и непротиворечивость данных на всех уровнях сети.
W3C и будущее семантической сети

Как и Всемирная паутина, семантическая сеть децентрализована - ни одна организация или агентство не может контролировать все ее правила и контент. Однако некоторые люди и организации взяли на себя руководящие роли в разработке руководств и протоколов Семантической паутины. К ним относятся Консорциум Всемирной паутины (W3C), его директор Тим Бернерс-Ли и его членские организации. W3C не является исследовательской организацией, поэтому университеты, другие организации и общественность также играют активную роль в разработке семантической паутины.
Некоторые области всемирной паутины уже включают компоненты семантической паутины. К ним относятся RSS-каналы, использующие RDF, и проект Friend-of-a-Friend (FOAF), который предлагает создавать машиночитаемые персональные веб-страницы.
Но большая часть функций и практичности Семантической паутины все еще находится в разработке, и есть некоторые довольно большие препятствия, которые необходимо преодолеть. Децентрализация дает разработчикам свободу создавать именно те теги и онтологии, которые им нужны. Но это также означает, что разные разработчики могут использовать разные теги для описания одного и того же, что может затруднить сравнение машин. Критики также ставят под сомнение «проблему идентичности» - представляет ли URI веб-страницу или концепцию или объект, описываемый страницей. Например, "http://www.starwars.com" означает фильмы о "Звездных войнах" или просто веб-страницу?
Некоторые разработчики расходятся во мнениях относительно того, следует ли Семантической паутине больше полагаться на правила или онтологии. Критики также говорят, что проект крайне непрактичен. Во-первых, люди на самом деле не думают о графах, которые использует RDF. Во-вторых, маловероятно, что компании и существующие сайты действительно потратят время и ресурсы, необходимые для добавления всех необходимых метаданных. В будущем стандартное программное обеспечение может включать опции для добавления метаданных при создании новых документов, но этот инструмент по-прежнему может не сделать проект осуществимым в более крупном масштабе.